6 min to read
Access Control Using Facial Recognition
Access Control Using Facial Recognition

Introduction
An efficient and accurate access control system is very important for many security applications. At present, for general identification techniques, there are two type of techniques non-biometric and biometric techniques. Non-biometric techniques use password access cards to identify a person, whereas biometric techniques use fingerprint, iris or face recognition methods for personal identification. Biometric techniques are more efficient in the person identified as the nonbiometric techniques are extremely susceptible to rigging and stealing problems. The most efficient biometric technique is known to be the face recognition approach because of its ability to overcome the need for user cooperation. This ability gives face recognition an important advantage over iris and fingerprint biometric techniques. A lot of research is already done on this topic and many systems are already created. We will compare the most commonly used method with the method that we created.
Objective Of Work
The objective of this project is first to locate the face coordinates in the input image or a video frame. Then recognize that face by comparing to the existing database. This definition seems very easy but its implementation is complicated. A various number of factors such as scale definition, location, orientation, pose, luminous etc, make this more complex to implement and thus become a matter of concern for the researchers to work on it. Recognizing the face is even more challenging than detecting face because of so many factors. Even if there is a slight similarity between the faces of the system might not able to distinguish properly if the training is not accurate.
Methods
We have used two different methods for this problem:
- Facial Recognition Using Haar Cascade
- Facial Recognition Using BPN and LVQ
For the implementation, I have used the following tools:
- Python 3.6
- OpenCV 3.2.0
- Numpy
- Pillow
- Pickle
- gzib
Backpropagation
In artificial neural networks, we use backpropagation to calculate a gradient that is needed in the calculation of the weights to be used in the network. This method is used to train deep neural networks i.e. networks with more than one hidden layer. It is equivalent to automatic differentiation in reverse accumulation mode. It requires the derivative of the loss function with respect to the network output to be known, which typically (but not necessarily) means that the desired target value is known. For this reason, it is considered to be a supervised learning method.
LVQ
LVQ stands for Learning Vector Quantization. It is a prototype-based supervised classification algorithm. LVQ is the supervised counterpart of vector quantization systems.
Procedure
Pre- Processing
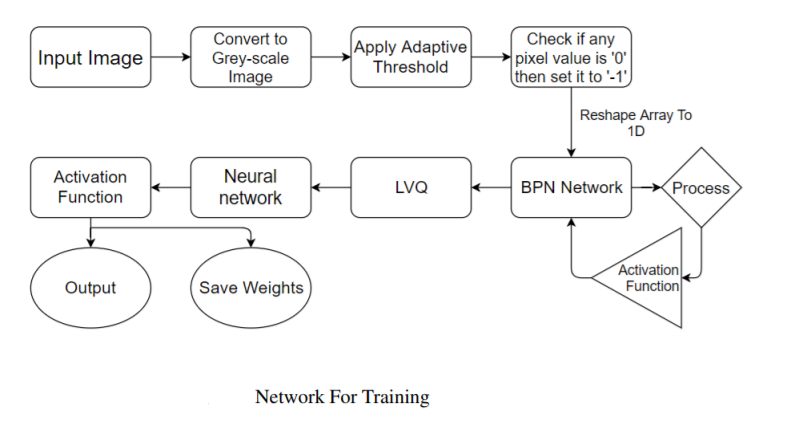
In the obtained database the image resolution is 680×480. If we take this as input then the total number of inputs will be 326,400 and we will be running it through multiple epoch which will take a lot of time and a lot of computing power. Therefore to save time we decrease the resolution and take image size 50×50 and crop only the faces so that it gives us better results.
Each photo is converted to grey-scale. This gives us the image in the form of an array with a value ranging from 0 to 255 in the single array element. If we directly send this as input then again it will take a lot of time as well as the value of weights will be very high so we set a threshold. If the value is above it then the cell value is +1 else -1.
If we take threshold 127 then with a slight change in lighting the result can change drastically. So to avoid it we have to use the Adaptive Threshold Method(Gaussian). In Gaussian Adaptive Threshold, the value is the weighted sum of neighbourhood values where weights are a Gaussian window.

Training
For training, we have taken 1050 input images(650 positive and 400 negative images). For a single image we have 2500 input nodes which are then passed to 200 hidden nodes and finally, there are 2500 output nodes. The target value for the BPN is given as the image itself. In this process, BPN is used as an auto-associative network. Here BPN is used to extract features of the face from the image.
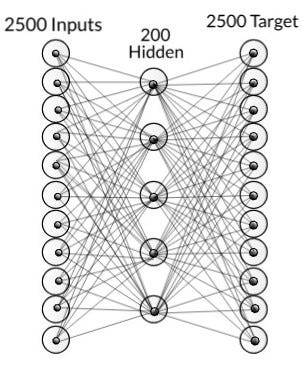
Network with just BPN
After the network is trained then the hidden nodes are taken as input and pass on to another network in which it is separated by using LVQ. The output has two nodes which tell whether the face is present or not. This is passed to another layer which is then passed to an activation function. This is the final output which tells us the probability of face present in that image.
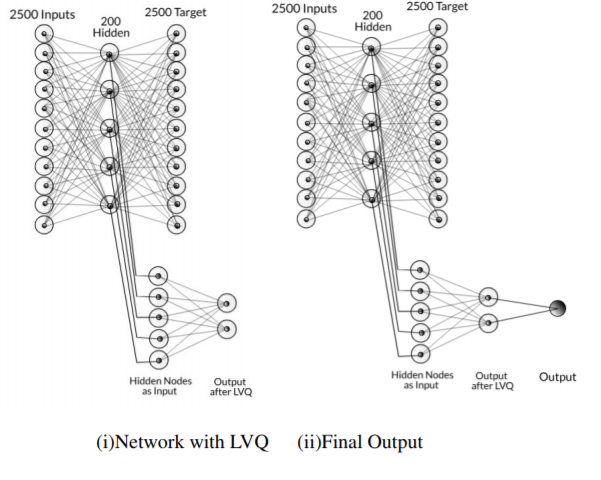
This whole process takes about 2hr to train the model(For 10 epoch per image). If we increase the number of epochs then the result will improve but the time taken will increase drastically(This might not be true for all the cases as at some point the error becomes constant and do not decreases).
All the trained data-set i.e weights are stored using pickle and gzib library.
Testing
For testing purpose from the database, we had already separated 550 images for testing which were not used as training database. We tested on around 550 positive images and 400 negative images. These images are also scaled to 50×50 in order to test.
As for the output mean result for positive training database the output had a value of 1.16 and for negative it was around 0.43.

For opening the pre-saved weights we use pickle library.
Result
Initially, the accuracy was 61% when the output of the hidden layer was considered as output. When another neural layer was attached then the accuracy increased to 65%. When the training data set was increased from 350 to 500 the accuracy increased to 72% and it takes around 0.096 sec to identify each image whether it is having a face or not.
This kind of network works better for identifying the identity of the person instead of detecting whether it is a face or not. Since this networks on extracting features and based on them give the output, therefore, it can be trained to give the identity of a person in form of binary or hexadecimal value.
Moreover, if we want to further improve the accuracy for face detection then we will have to increase the number of hidden layers but because of that the computation time will be higher and will not have real-world application as it will take time to show the result.




Comments