6 min to read
Access Control Using Facial Recognition
Advanced Face Detection and Recognition

Introduction
An efficient and accurate access control system is crucial for ensuring the security of sensitive applications. In today’s security landscape, identification methods can be broadly categorized into two types: non-biometric and biometric techniques.
Non-biometric techniques, such as password access cards, have been traditionally used for personal identification. However, these methods are prone to issues like rigging and theft, making them less reliable.
On the other hand, biometric techniques—which include fingerprint, iris, and face recognition—offer a more secure and efficient means of identifying individuals. Among these, face recognition stands out as the most effective biometric technique. Unlike iris and fingerprint recognition, face recognition does not require active user cooperation, providing a significant advantage in many security scenarios.
Given the extensive research in this field, numerous systems have already been developed. In this article, we will compare the most commonly used face recognition methods with our newly developed approach to demonstrate the advancements in this technology.
Objective Of Work
The primary objective of this project is to accurately detect and recognize faces within an input image or video frame. This process involves two key steps: first, identifying the face coordinates, and second, matching the detected face against an existing database for recognition.
While this may sound straightforward, the implementation is highly complex. Various factors, such as scale, location, orientation, pose, and lighting conditions, introduce significant challenges. These complexities make face recognition a more difficult task compared to face detection, as even minor similarities between faces can lead to misidentification if the training process is not sufficiently precise.
This project aims to address these challenges and improve the accuracy of face recognition systems, which remains a critical area of research.
Methods
To address the problem of facial recognition, we employed two distinct methods:
- Facial Recognition Using Haar Cascade
- Facial Recognition Using BPN and LVQ
For the implementation, I have used the following tools:
- Python 3.6: The programming language used for the entire project.
- OpenCV 3.2.0: For image and video processing.
- Numpy: To handle numerical data and arrays.
- Pillow: For image manipulation.
- Pickle: For serializing and deserializing Python objects.
- gzib: To compress and decompress data files.
Backpropagation
Backpropagation is a critical algorithm used in artificial neural networks to calculate the gradient needed for adjusting the weights within the network. This technique is essential for training deep neural networks, which are networks that contain more than one hidden layer.
Backpropagation works by performing automatic differentiation in reverse accumulation mode. It requires knowledge of the derivative of the loss function with respect to the network’s output. Typically, this involves knowing the desired target values, making backpropagation a supervised learning method.
LVQ
LVQ stands for Learning Vector Quantization. It is a prototype-based supervised classification algorithm. LVQ is the supervised counterpart of vector quantization systems.
Procedure
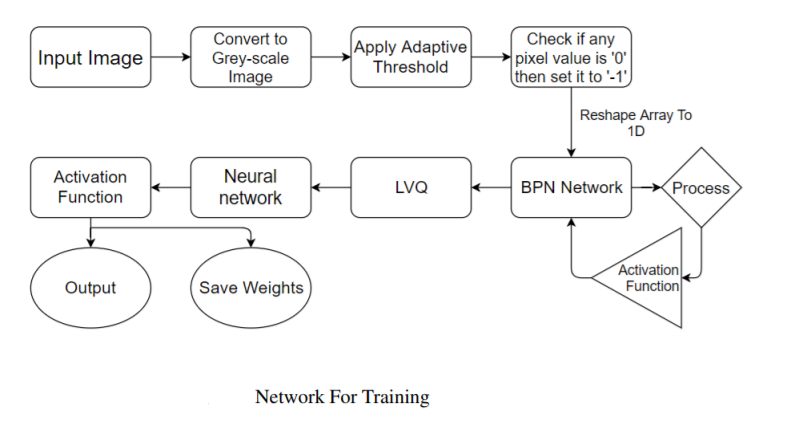
In our database, the original image resolution is 680×480. Processing images at this resolution would require handling 326,400 inputs per image, which would demand significant computing power and time, especially when running multiple epochs. To optimize performance, we reduce the resolution to 50×50 pixels and crop the images to focus solely on the faces, enhancing both speed and accuracy.
Each image is then converted to grayscale, resulting in an array of pixel values ranging from 0 to 255. However, processing these raw values directly would again be computationally expensive and could lead to excessively high weight values. To address this, we apply a thresholding technique: pixel values above the threshold are set to +1, and those below are set to -1.
Using a fixed threshold (e.g., 127) can lead to inconsistent results due to variations in lighting. To mitigate this, we utilize the Adaptive Thresholding method, specifically the Gaussian Adaptive Threshold. This approach calculates the threshold value as the weighted sum of the surrounding pixel values, using a Gaussian window to ensure more stable and accurate results under varying lighting conditions.

Training
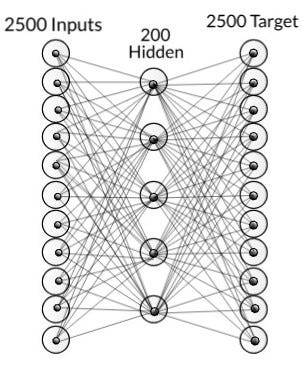
For training, we used a dataset consisting of 1050 images, with 650 positive images (containing faces) and 400 negative images (without faces). Each image is processed into 2,500 input nodes, which are then passed through 200 hidden nodes before reaching 2,500 output nodes. The target value for the Backpropagation Network (BPN) is the image itself, making BPN function as an auto-associative network in this context.
In this setup, BPN is employed to extract facial features from the images, enabling the network to recognize and differentiate between faces effectively.
After the network is trained then the hidden nodes are taken as input and pass on to another network in which it is separated by using LVQ. The output has two nodes which tell whether the face is present or not. This is passed to another layer which is then passed to an activation function. This is the final output which tells us the probability of face present in that image.
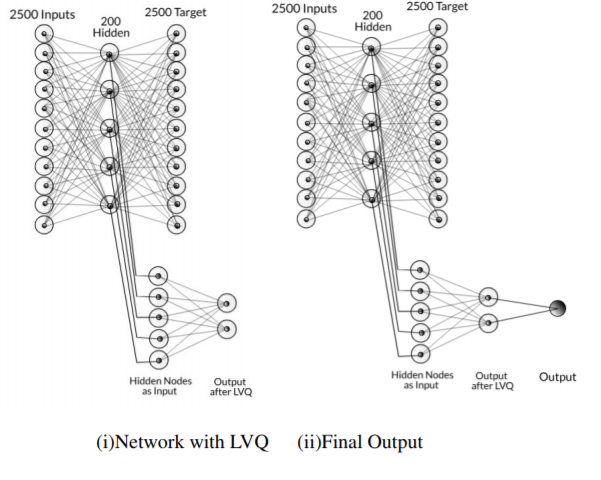
This whole process takes about 2hr to train the model(For 10 epoch per image). If we increase the number of epochs then the result will improve but the time taken will increase drastically(This might not be true for all the cases as at some point the error becomes constant and do not decreases).
All the trained data-set i.e weights are stored using pickle and gzib library.
Testing
For testing purposes, we set aside 550 images from the database that were not included in the training set. This test set consisted of approximately 550 positive images (containing faces) and 400 negative images (without faces). To ensure consistency, these images were also scaled to 50×50 pixels.
The testing results were promising: the mean output value for the positive test images was 1.16, while the mean output for the negative images was around 0.43. These results demonstrate the model’s ability to distinguish between positive and negative samples effectively.

For opening the pre-saved weights we use pickle library.
Result
Initially, the model achieved an accuracy of 61% when the output from the hidden layer was used directly. By adding another neural layer, the accuracy improved to 65%. Further improvements were observed when the training dataset size was increased from 350 to 500 images, boosting the accuracy to 72%. The model takes approximately 0.096 seconds to identify whether an image contains a face.
This type of neural network is particularly effective for identifying the identity of a person, rather than just detecting the presence of a face. Since the network focuses on extracting and analyzing facial features, it can be trained to output the identity of a person in binary or hexadecimal format.
However, to further enhance face detection accuracy, increasing the number of hidden layers could be beneficial. The trade-off, though, is that more hidden layers would significantly increase computation time, potentially making the system impractical for real-world applications due to delays in delivering results.




Comments